上一篇提到數據預處理的章節
本篇繼續從Missing Data(缺失數據)開始
缺失數據是常見的數據集問題之一, 也就是數據集並不完整
可能遺漏了某部分數據, 那遺漏的部分會需要預先處理
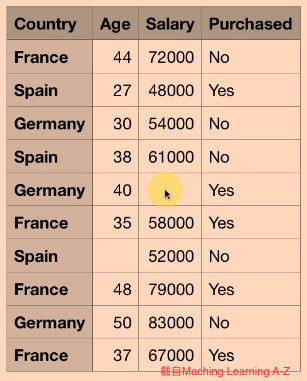
本節會用到的資料如下, 可以看到空格的部分就是缺失之處
處理遺失數據的方法:
我們使用class sklearn.impute.SimpleImputer 來實現這個目的
可以利用descriptive statistic(描述性的數據) along each column 來填missing values
例如: mean, median, or most frequent
SimpleImputer 已經被拿來取代以前的 sklearn.preprocessing.Imputer

Parameters:
X is not an array of floating values;X is encoded as a CSR matrix;add_indicator=True.上面是創建一個simpleimputer object
接下來可以使用fit() and tranform() 來補足missing data

fit() 要帶入目標矩陣,用來init imputer, sample 中的 X[:,1:3] 代表取所有的row數, 取1~2column (i.e purchased 欄位不取)
transform() 帶入相同的參數, 可以轉出imputer 資料, 最後成功替換missing data in X 矩陣
#from sklearn.preprocessing import Imputer >> invlaid now
from sklearn.impute import SimpleImputer
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Data.csv')
x = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
# only deal with column 1, 2 (not includes 3)
imputer = imputer.fit(x[:,1:3])
x[:, 1:3] = imputer.transform(x[:, 1:3])
print(x)
print("-----")
最後資料如下圖, 可以看到原本第五筆資料的Salary 欄位跟第七筆資料的Age欄位都是遺失的
現在已經被填入平均age 和 平均salary了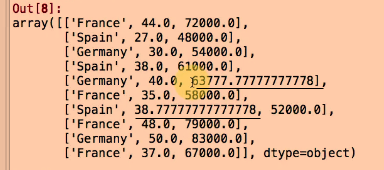
https://scikit-learn.org/stable/modules/generated/sklearn.impute.SimpleImputer.html


 iThome鐵人賽
iThome鐵人賽